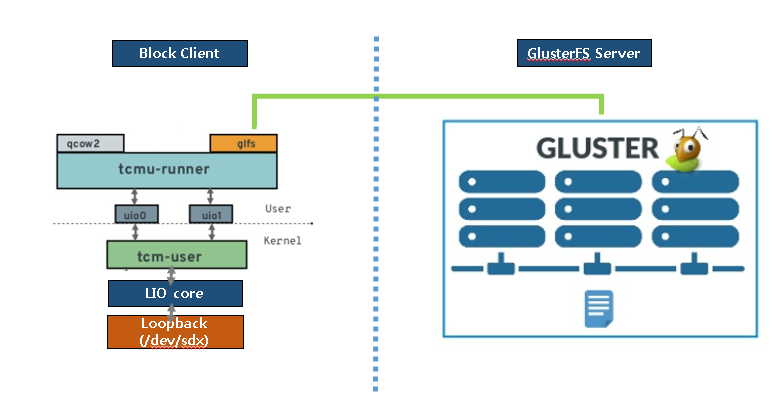
Revisting iscsi target hung issue with tcmu glusterfs backstore
解决问题的思路反思和教训
2019 年 0710 生成此报告,20200525 再次审视。
不光需要理解代码,也应该有假设探索的能力,才能快速准确的定位解决 bug。反思自己以下的解决过程,在代码理解和 bug 的复现的基础上结合一定的假设,也许就可以更快的分析解决这个问题了。
- 问题复现上,由于缺乏当时生产环境的具体信息,确实只能自我摸索。但其实已经极限接近问题的本质了,但最后却浅尝辄止了
- 在代码理解上,精读分析了代码。却没有跳出具体细节。从直观或者宏观角度做一个假设,进而换个角度理解或者给 bug 复现探索提供新的思路
问题
三台机器,243,244,245 IO 的时候有些 target 的 iscsi 会话断开,target hung。
gluster-block 创建一个 glfs backstore,基于此 backstore 创建一个 lun,期间默认会创建 tpg 和 portal,这里 HA=1。然后通过 targetcli 在此 tgp 和 portal 下创建其他 lun。默认 gluster-block 在一个 tpg 下只会创建一个 lun,这里我们利用了 targetcli 的方式,创建其他 lun。
如此,在组成 gluster volume 的这三台机器,每个都这么执行如上操作。 本质上生成了三个 target 即三个 iqn。
每个 target 对应一个机器,每个 target 一个 tpg,这个 tpg 下面有多个 lun。
i 端(另外机器)连上三个 target,轮流读写这些 lun。
现象
- 244/245 机器当前的 target 与某个 i 端的连接处于 close-wait 状态,而 243 机器所有的 i-t 连接都是正常 est 状态。
- 244 机器 np 线程 接收队列满了。245 未观察。
[root@xdfs2 ~]# ss -n4lt 'sport = :iscsi-target'
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 257 256 192.168.227.244:3260- 244/245 机器 np/trx/ttx 线程 fd count
ls /proc/*/fd|wc -l
数据获取错误,忽略 - iscsiadm -m discovery
在 244 机器上执行 iscsiadm -m discovery -t st -p 192.168.227.245/244 -d8 连接超时,243 正常。
iscsiadm -m discovery -t st -p 192.168.227.243 输出三个 target iqn,688d0c0a,ada71018(这个是 block 创建的), 8132c0d0 - iscsiadm -m session
在 243 机器上 iscsiadm -m session,no active session,说明此机器没有发起过或者没有 logging session。
在 244 上执行 iscsiadm -m session -P 3
三个 session,conn state 和 session state 都是 logged in 状态。
一个是连到 245 target 7a734 的 session。sid =1
一个是连到 244 即本机的 target d6726 的 session。sid=2 (block 创建的)
一个是连到 244 即本机的 target 0d7c4b 的 session。sid =3
243 : block 创建的是 ada71018-8d55-4106-9787-17f7df92c643
244: block 创建的是 d672686d-dda6-4c31-ace6-4db75e9e12d3 - D 状态,只有 243 机器没有 D 状态,244/245 偶尔有 glusterfs/glusterfsd D 状态,但是正常的。
244/245 有以下 hang,
244 机器
scsit [iscsi_ttx] 18041 D
iscsit [iscsi_np] 21181 D
[root@xdfs2 ~]# cat /proc/21181/stack
[<ffffffffc07c5c48>] iscsit_stop_session+0x1c8/0x1e0 [iscsi_target_mod]
[<ffffffffc07b67d3>] iscsi_check_for_session_reinstatement+0x213/0x280 [iscsi_target_mod]
[<ffffffffc07b95d5>] iscsi_target_check_for_existing_instances+0x35/0x40 [iscsi_target_mod]
[<ffffffffc07b96d9>] iscsi_target_do_login+0xf9/0x640 [iscsi_target_mod]
[<ffffffffc07ba836>] iscsi_target_start_negotiation+0x56/0xc0 [iscsi_target_mod]
[<ffffffffc07b824e>] __iscsi_target_login_thread+0x89e/0x1000 [iscsi_target_mod]
[<ffffffffc07b89d8>] iscsi_target_login_thread+0x28/0x60 [iscsi_target_mod]
[<ffffffffb62c1c31>] kthread+0xd1/0xe0
[<ffffffffb6974c37>] ret_from_fork_nospec_end+0x0/0x39
[<ffffffffffffffff>] 0xffffffffffffffff
[root@xdfs2 ~]# cat /proc/18041/stack
[<ffffffffc07be837>] iscsit_check_session_usage_count+0x87/0x90 [iscsi_target_mod]
[<ffffffffc07c6665>] iscsit_close_session+0x165/0x230 [iscsi_target_mod]
[<ffffffffc07cc522>] lio_tpg_close_session+0x12/0x20 [iscsi_target_mod]
[<ffffffffc0811c8c>] target_release_session+0x2c/0x30
[target_core_mod]
[<ffffffffc0813cec>] target_put_session+0x2c/0x30 [target_core_mod]
[<ffffffffc07c67fe>] iscsit_logout_post_handler+0xce/0x260 [iscsi_target_mod]
[<ffffffffc07c6a66>] iscsit_response_queue+0xd6/0x730 [iscsi_target_mod]
[<ffffffffc07c56df>] iscsi_target_tx_thread+0x1bf/0x240 [iscsi_target_mod]
[<ffffffffb62c1c31>] kthread+0xd1/0xe0
[<ffffffffb6974c37>] ret_from_fork_nospec_end+0x0/0x39
[<ffffffffffffffff>] 0xffffffffffffffff245 机器
iscsit [iscsi_np] 25620 D
[root@xdfs3 ~]# cat /proc/25620/stack
[<ffffffffc0851c48>] iscsit_stop_session+0x1c8/0x1e0 [iscsi_target_mod]
[<ffffffffc08427d3>] iscsi_check_for_session_reinstatement+0x213/0x280 [iscsi_target_mod]
[<ffffffffc08455d5>] iscsi_target_check_for_existing_instances+0x35/0x40 [iscsi_target_mod]
[<ffffffffc08456d9>] iscsi_target_do_login+0xf9/0x640 [iscsi_target_mod]
[<ffffffffc0846836>] iscsi_target_start_negotiation+0x56/0xc0 [iscsi_target_mod]
[<ffffffffc084424e>] __iscsi_target_login_thread+0x89e/0x1000 [iscsi_target_mod]
[<ffffffffc08449d8>] iscsi_target_login_thread+0x28/0x60 [iscsi_target_mod]
[<ffffffff962c1c31>] kthread+0xd1/0xe0
[<ffffffff96974c37>] ret_from_fork_nospec_end+0x0/0x39
[<ffffffffffffffff>] 0xffffffffffffffff进程状态
gluster-blockd--- active(running)
gluster-block-target--- active(exited)
target ---- inactive(dead) 应该 active(running) ?需要关注
tcmu-runner —active-running
kernel trigger blocked thread to print call trace
与 cat /proc/*/stack 结果一致。
分析
接收队列满
试图设置更高的值,发现系统默认 net.core.somaxconn = 128,而且内核 target 代码设置 SCSIT_TCP_BACKLOG = 256 应该是合理的。一个疑问:somaxconn 是最大值,SCSIT_TCP_BACKLOG 怎么会超过呢?倾向于认为接收队列满是因为 hung 导致的。
根据 call trace 搜寻一些 commit, 未果
模拟复现
根据 244 机器,一个正常 login 过程,一个属于 logout 过程。分析 calltrace,两个 calltrace 独立,互相不影响(?)。我们试图模拟出 login- perform reinstatement,本质就是 i 端登录失败后自己 relogin,内部机制,不是我们手动 relogin。
排除 tcmu,利用 target backstore type pscsi,使用 scsi_debug 模拟的盘进行测试:
在一定读写次数 (scsi_debug 参数 every_nth = 30) 后,/dev/sda 会忽略读写(scsi_debug 参数 opts = 0x4 表示忽略此 cmd,不返回),即永久超时。I 端大约在一定时间(由 device timeout 时间决定)后触发自己的超时机制,再次检查确认命令超时后会发送 abort (abort 前面那个超时的 cmd)给 target。由于 I 端设置 abort 的超时时间是 5s,但是后端即 target 的 /dev/sda 设备执行 abort 的时间设置为 120s-650s 之间(比如 scsi_debug 参数 abort_sleep = 120),导致 I 端 abort 失败。I 端进而发送 reset lun,然后 reset target ,并试图 reset session,等待 relogin,期间会进行 session recovery 。失败的话,会 offline device。在 i 端设置
- echo 5 > /sys/block/sda/device/timeout 默认 30s,i 端读写的时候一般要大约超时 180s 后才可能触发超时,然后重复确认,进而 abort/reset 等,时间比较长。为了复现尽可能快,设置为 5s。
- node.session.timeo.replacement_timeout = 5 , 默认 120s
- node.conn[0].timeo.login_timeout = 30,默认 15s
- node.conn[0].timeo.noop_out_timeout and 未改变
node.conn[0].timeo.noop_out_interval = 5 未改变 - node.session.err_timeo.abort_timeout = 5 默认 15s
2-4 项是 i 端的 /etc/iscsi/iscsid.conf 配置,replacement_timeout 是 recovery session 的 timeout 时间。
abort_timeout 表示 abort 命令的超时时间。noop_out_timeout 表示发送 ping 到 target 端的超时时间,间隔 noop_out_interval 5s 再次发送。
复现情况:
复现出与原来烽火 bug 相同的 np 线程 hung。但是在大约一定时间后,np 又恢复正常。 具体与后端实际 hung 的时间有关,对于我们这个测试,就是与 abort_sleep 有关。
也试图改变测试条件,但最终也没有复现出一直 hung 的情况。
在 np 卡住的时候,命令行 I 端登录 target,没有立即完成,这时持续 ctrl+c 。持续多次登录 +ctrlC,直至 target 的 3260 端口 listen sock 的 accept 队列变满,同时所有 I-T 连接处于 closewait 状态。
从这点来看,基本能复现出 accept 队列满。说明是 np 卡住或者某种原因来不及关闭已经建立的 sock,出现 closewait。但线上问题是只出现一个 closewait 状态,且 listen sock 的 accept 队列也满了。单 brick glusterfs I -T 环境:
手动配置的 target,不是通过 gluster-block 配置。具体差别有/sys/kernel/config/target/core/user_1/dust2lun/attrib/cmd_time_out gluster-block 130s 配置,手动默认配置是 30s。
/sys/kernel/config/target/core/user_1/dust2lun/attrib/max_data_area_mb gluster-block 配置 64MB,而手动默认配置是 1024MB,期间也进行了 1MB 的测试。
a 编译内核模块 dm_dust 模拟一些坏扇区进行测试。参数手动默认。没有出现 hung 的情况,只是 i 端 io 时有 input/output ERROR. 放弃测试。(可以试试持续 loop io 时,即使出现错误情况下也持续 io,类似于下面的测试)。
b 创建 lvm 或者 dm 设备作为 brick,I 端登录后在 brick 机器执行 dmsetup suspend dmdevice ,暂停 brick io
- 手动默认参数情况下,即 cmd_time_out=30,max_data_area_mb=1024MB 下
I 端持续 io 情况下,t 端没有发现任何 D 状态出现。
初步认为是 tcmu 的 cmd_time_out 超时机制导致 target 给 i 端返回错误,规避了 target 的 backstore hung 的情况。对于非 tcmu 的 target,由于没有类似的超时机制,一切的超时处理都由 i 端实现。 - 手动默认参数情况下,即 cmd_time_out=30,max_data_area_mb=1MB, 测试在 ringbuffer 满的情况下即极端或者异常情况
发现在 libaio,direct=0 的情况下,很快 target 的 tcmu 的 ringbuffer 用满了,进而好多 cmd 排队。只是影响性能,并没有出现 io 错误等,也没有 hung 的情况(在当时的测试环境下)
在 libaio,direct=1 下,估计后端存储性能不强,没有出现 ringbuffer 用满了的情况,也没有 hung 出现。 - cmd_time_out=120,max_data_area_mb=1MB, node.session.timeo.replacement_timeout = 10
为了让在 tcmu 情况下也出现 hung 的情况,分析了 target/i 端的 pscsi/tcmu 下的 debug log 和代码,试图设置 target 端的 set attribute login_timeout=10(目的是触发 target login timeout),以前设置的值是 15s,发现设置没有成功。然后设置 tcmu cmd_time_out=120/130(这个时间长了也会触发 target login timeout,与 pscsi 情况就有可能相同)。同时设置 node.session.timeo.replacement_timeout = 10,增加了原来 5s 的设置,延长 target 时间来恢复。
在 libaio,direct=1 下,每隔 1s watch 进程状态,发现出现了 np 和 trx 的 D 状态。而且持续时间很长。但是可能是 cmd_time_out 设置的时间的问题,基本都是在一定时间比如小于 120s 后就又恢复为 S 状态,然后就又 D 状态一段时间。所以 dmesg 里并不会出现 np 等的 hung call trace,只是有当时 suspend brick 出现的 glusterfs io thread 线程的 call trace。
- 手动默认参数情况下,即 cmd_time_out=30,max_data_area_mb=1024MB 下
初步结论
- 后端 hung,一般也会导致 np hung,但是目前只是复现出几乎 hung 的情况,并没有完全复现出。因为 cmd_time_out 存在,不会一直不返回的。
- 假如后端 hung,还需要去修复 glusterfs 自身的问题。即然具有了 1 的 cmd_time_out 的功能,2 也不会是原因。
- 至于 target 自身,包括 tcmu 的问题导致的 hung,也没有复现出,但有可能需要以下 bug 修复。可以采纳或者以验证的方式采用。
Revist:
对于 3,应该发散思维或者多找不同观点的同事或者朋友来沟通,也许才能最终找到本质问题。 虽然代码已经彻底分析了,但却不明了问题的解决方向在哪。事后看来,才感叹原来好像很明显啊。
其实 1 和 2 已经表明问题的本质在 3. 其实从 stacktrace 角度和代码角度是很有可能作出是多个线程 (logout 线程、login 线程)等待一个资源,最后 hang 的问题。也试图在这方面进行多方面的尝试,具体可见下文。最终复现的方式是在在 logout 的同时,disable tpg 即 iscsit_free_session,其实与那个 login 线程里做的具体事情一样,最终都调用 iscsi_check_for_session_reinstatement。但由于对问题本质的不深刻把握,导致复现一直限于 logout/login 线程,不能直接的复现出来。
可能的 bug 修复
lost wakeup
target 本身就 hung
Disclaimer: I do not understand why this problem did not show up before tcp prequeue removal.我们内核并没有删除 tcp prequeue,所以应该不会触发这个 bug。
不过可以试试 sysctl tcp_low_latency=1 (不走 tcp prequeue 路径)验证是否 workaround hung 问题。
2. cmd 丢失超时问题
scsi: tcmu: avoid cmd/qfull timers updated whenever a new cmd comes
此 patch 解决了 tcmu 内核模块丢失某些 cmd 的超时 timer,有可能让某些 cmd 永远不返回,np hung。
一些概念和需要注意的
max_data_area_mb per lun
tcmu 本身默认设置 1024MB,但 gluster-block 设置为 64MB。
一个 scsi cmd 的控制部分基本是固定的,可变的是每个 scsi cmd 的数据 buffer。1G data area 基本上 8M cmd area。
target 总的大小默认是 2GB。
对于高 iops,低吞吐量的 IO,可以采用 64MB 的 gluter-block 的设置,但对于高吞吐量的 IO,应该设置大些。
否则应该会有好多问题出现。tcmu cmd_time_out 设置
a cmd_time_out=0, 以前 gluster block 默认设置
Setting cmd_time_out to 0 means that the iscsi_trx will wait infinite until the cmds fired to tcmu-runner return back. Just in case if tcmu-runner is killed/terminated, the iscsi_trx will hung in D state infinitely。link
即使设置 cmd_time_out >0, 如果某些 cmd 丢失超时设置,也会导致 D 状态。b cmd_time_out > 0
内核 tcmu cmd 超时机制,正常情况下即使 glusterfs hung,也不会导致 np 完全 hung 住
alua HA 下 cmd_time_out 必须满足,cmd_time_out > GLUSTER ping timeout 42/5s(我们的设置) && cmd_time_out > replacement_timeout。alua ha> 1 时,cmd_time_out 必须大于 replacement_timeout,以便 alua 路径正常恢复。 gluster-block 配置 cmd_time_out= 130s,replacement_timeout=120s。也必须大于 glusterfs ping timeout 42/(5s 是我们的 glusterfs 的设置)。
在 brick hung 或者 tcmurunner hung/killed 时,target 会阻塞 130s(这时会有 D 状态也会有 dmesg blocekd 120s call trace 打印)。然后试图恢复。
如下是 cmd_time_out 与 replacement_timeout 的关系的解释
alua ha=1 时,分析 i 端 iscsi 内核代码,cmd_time_out 与 replacement_timeout 应该没有任何关系。
烽火线上配置是 cmd_time_out= 130s,replacement_timeout = 120s (假设客户用的标准 I 端程序),配置与 HA >1 时的相同。
在设置 cmd_time_out=30s,replacement_timeout=5s 下,np 不 hung,也能登录成功。具体流程如下 tcmu session reinstatement target 端的流程- 45:38 recv abort_task
- 45:43 rx=0
- 45:45 take action for connect exit
cleanup_wait status ,close nection 0 on sid 1816
transportgeneric free cmd detect cmd_t_aborted for its - 5:45 recv login, sid1816 acitive,perf session reinstatement.
- 45:58 cmu_cmd_timedout:1287: dust2lun cmd timeout has expired
target_core_user:tcmu_check_expired_cmd:1267: Timing out cmd 38 on dev dust2lun that is inflight.
_transport_wait_for_tasks:3026: wait_for_tasks: Stopped wait_for_completion(&cmd- >t_transport_stop_comp) for ITT: 0x80000009
ABORT_TASK: Sending TMR_FUNCTION_COMPLETE for ref_tag: 2147483657 1's
lio_release_cmd
iscsit_close_connection
iscsit_close_session
完成 session resinstatement
Sending Login Response (成功)如上流程第 4 步之后大约 13s 后,cmd_time_out 超时定时器失效,释放 cmd,释放原来的资源引用,session reinstatement 成功,登录成功。
对于 pscsi 测试情况,第四步 15s 后(即触发 target login timeout handler)导致 target 关闭自己的 socket,失败 session resinstatement,登录失败。
如果设置 cmd_time_out=130s,replacement_timeout=5s/10s 时,np hung 。如模拟复现部分 ---- 单 brick glusterfs I -T 环境项的最后一个复现条件。(可以测试 replacement_timeout=120s 下,类似烽火环境)
iscsi 登录过程理解,特别是 target 端的处理逻辑,可以参考这个 maillist 和对于的 RFC(具体的实现可能比 RFC 里的介绍的少)
Todo:
- 设置 i 端 logintimout 再小点可否复现? 而不是 target 端 login timeout, 试试?
- HA=1 时,到底是什么影响?cmd_time_out 应该小于 还是大于 replacement_timeout?
- 生产复现时打开 i 端,target 端调试
target:
echo -n 'module iscsi_target_mod =pflmt; module target_core_mod =pflmt; module target_core_user =pflmt; module uio =pflmt' > /sys/kernel/debug/dynamic_debug/controli:
echo -n 'module libiscsi =pflmt; module libiscsi_tcp =pflmt; module scsi_transport_iscsi =pflmt; module iscsi_tcp =pflmt' > /sys/kernel/debug/dynamic_debug/control
echo 1 > /sys/module/iscsi_tcp/parameters/debug_iscsi_tcp
echo 1 > /sys/module/libiscsi/parameters/debug_libiscsi_conn
echo 1 > /sys/module/libiscsi/parameters/debug_libiscsi_eh
echo 1 > /sys/module/libiscsi/parameters/debug_libiscsi_session
echo 1 > /sys/module/scsi_transport_iscsi/parameters/debug_conn
echo 1 > /sys/module/scsi_transport_iscsi/parameters/debug_session
echo 1 > /sys/module/libiscsi_tcp/parameters/debug_libiscsi_tcp- 生产 / 复现时要 stop gluster-blockd 和 gluster-block-target,防止干扰。或者开启,以便确认是否干扰导致的 hung。
- I 端用标准客户端时有个 bug,在 io 的时候 logout 然后 login,会导致发现的设备异常,要恢复正常的话,目前只能重启机器。正在定位。并提交 bug https://bugzilla.redhat.com/show_bug.cgi?id=1726051
- 生产 / 复现时需要关注 target service 状态 ,验证 glusterfs 是否真正正常(reboot gluster volume 等)。采用 cat lun image 文件好像不能完全确定是否有问题。 还有上次 statedump 竟然没有文件输出。
- 严格按照烽火环境参数配置测试。
- target kernel warning
_iscsit_free_cmd+0x26e/0x290需要 定位
Revist: 名为 todo,其实是没有继续这个问题的定位,而是放弃了。
20200525 的 revisit
好奇现在是否社区已经解决了,从现在翻看回 201907 月份的 maillist。找到问题的解决方案了。
scsi: target: fix hang when multiple threads try to destroy the same iscsi session
LIO hanging in iscsit_free_session and iscsit_stop_session
其实也是与原来 stacktrace 和代码分析一致,只是没能从这个角度去有意的变通,去设计测试例。当然如果是一直是 target-devel/iscsi 的维护者,应该会有充分的经验能判断出问题所在。
这个问题看社区估计从 2018 年就有出现这个问题,但最终解决还是在 20200312.
A small favor
Was anything I wrote confusing, outdated, or incorrect? Please let me know! Just write a few words below and I'll be sure to amend this post with your suggestions.
Follow along
If you want to know about new posts, add your email below. Alternatively, you can subscribe with RSS.