Millions of Tiny Databases
what production to build
the configuration store for a high-performance cloud block storage system (Amazon EBS).
requirement
This database needs to be not only highly available, durable, and scalable but also strongly consistent. We quickly realized that the constraints on availability imposed by the CAP theorem, and the realities of operating distributed systems, meant that we didn’t want one database. We wanted millions
what is physalia
Physalia is a transactional key-value store, optimized for use in large-scale cloud control planes, which takes advantage of knowledge of transaction patterns and infrastructure design to offer both high availability and strong consistency to millions of clients. Physalia uses its knowledge of datacenter topology to place data where it is most likely to be available. Instead of being highly available for all keys to all clients, Physalia focuses on being extremely available for only the keys it knows each client needs, from the perspective of that client.
physalia use cases
distributed systems problems like control planes, configuration management, and service discovery.
large-scale cloud control planes
transaction patterns
infrastructure design
defect of Traditional architectures for highly-available systems,Most modern system designs,
assumption: infrastructure failures are statistically independent, and that it is extremely unlikely for a large number of servers to fail at the same time.
Most modern system designs are aware of broad failure domains (data centers or availability zones), but still assume two modes of failure: a complete failure of a datacenter, or a random uncorrelated failure of a server, disk or other infrastructure. These assumptions are reasonable for most kinds of systems.
in traditional datacenter environments, probability of second disk failure
while the probability of a second disk failure in a week was up to 9x higher when
a first failure had already occurred, this correlation drops off to less than 1.5x as systems age. While a 9x higher failure rate within the following week indicates some correlation, it is still very rare for two disks to fail at the same time. This is just as well, because systems like RAID [43] and primarybackup failover perform well when failures are independent, but poorly when failures occur in bursts
how measured the availability of system
a simple percentage of the time that the system is available (such as 99.95%), and set Service Level Agreements (SLAs) and internal goals around this percentage.
AWS EC2 Availability Zones
named units of capacity with clear expectations and SLAs around correlated failure, corresponding to the datacenters that customers were already familiar with.
aws thinking history on failure and availability
2006 measure available
2008 availability zone(corrleated failure)
now blast radius and correlation of failure
Not only do we work to make outages rare and short, we work to reduce the number of resources and customers that they affect [55], an approach we call blast radius reduction. This philosophy is reflected in everything from the size of our datacenters [30], to the design of our services, to operational practices.
How aws minimizes the blast radius of failures
https://www.youtube.com/watch?v=swQbA4zub20
sizing of database
https://www.youtube.com/watch?v=AyOAjFNPAbA
ebs
Amazon Elastic Block Storage (EBS) is a block storage service for use with AWS EC2, allowing customers to create block devices on demand and attach them to their AWS EC2 instances.
volume failure define
volumes are designed for an annual failure rate (AFR) of between 0.1% and 0.2%, where failure refers to a complete or partial loss of the volume. This is significantly lower than the AFR of typical disk drives [44].
how ebs acheive higher volume avalibility
EBS achieves this higher durability through replication, implementing a
chain replication scheme (similar to the one described by van
Renesse, et al [54]).
https://dl.acm.org/doi/10.5555/1251254.1251261
https://www.usenix.org/legacy/publications/library/proceedings/osdi04/tech/full_papers/renesse/renesse.pdf
Chain Replication for SupportingHigh Throughput and Availability
replication group??
ebs arch
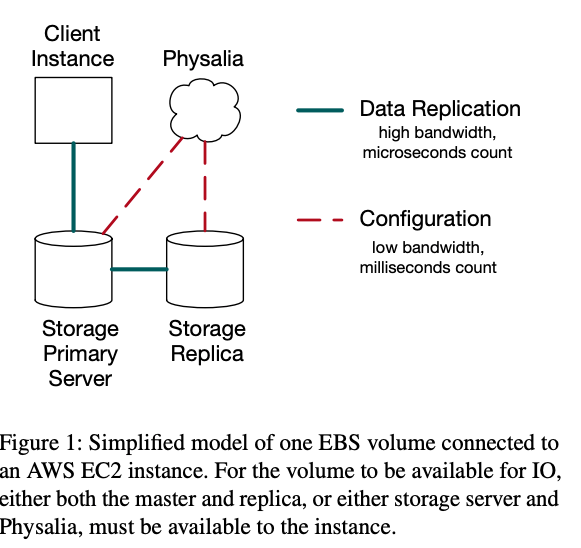
In normal operation (of this simplified model), replicated data flows through the chain from client, to primary, to replica, with no need for coordination. When failures occur, such as the failure of the primary server, this scheme requires the services of a configuration master, which ensures that updates to the order and membership of the replication group occur atomically, are well ordered, and follow the rules needed to ensure durability. To fail gracefully and partially, and strongly avoid large-scale failures.
ebs search
Simworld aws
The deatailed requirements on configuration master Physalia
In normal operation it handles little traffic, as replication continues to operate with no need to contact the configuration master. However, when large-scale failures (such as power failures or network partitions) happen, a large number of servers can go offline at once, requiring the master to do a burst of work. This work is latency critical, because volume IO is blocked until it is complete. It requires strong consistency, because any eventual consistency would make the replication protocol incorrect. It is also most critical at the most challenging time: during large-scale failures.
Volume replication protocol is in the ebs storage server not in the physalia.
Physalia is a specialized database designed to play this role in EBS, and other similar systems at Amazon Web Services. Physalia offers both consistency and high availability, even in the presence of network partitions, as well as minimized blast radius of failures. It aims to fail gracefully and partially, and
strongly avoid large-scale failures.
the EBS control plane and On 21 April 2011 outage and blast radius
Replication configuration was stored in the EBS control plane these days
When data for a volume needs to be re-mirrored, a negotiation must take place between the AWS EC2 instance, the EBS nodes with the volume data, and the EBS control plane (which acts as an authority in this process) so that only one copy of the data is designated as the primary replica and recognized by the AWS EC2 instance as the place where all accesses should be sent.
This provides strong consistency of EBS volumes. As more EBS nodes
continued to fail because of the race condition described above, the volume of such negotiations with the EBS control plane increased. Because data was not being successfully re-mirrored, the number of these calls increased as the system retried and new requests came in. The load caused a brown out of the EBS control plane and again affected EBS APIs across the Region.
This failure vector was the inspiration behind Physalia’s design goal of limiting the blast radius of failures, including overload, software bugs, and infrastructure failures.
CAP consistency availability partition tolerance for physalia
As proven by Gilbert and Lynch [22], it is not possible for a distributed system to offer both strong consistency (in the sense of linearizability [31]), and be available to all clients in the presence of network partitions. Unfortunately, all realworld distributed systems must operate in the presence of
network partitions [6], so systems must choose between strong consistency and availability.
Strong consistency is nonnegotiable in Physalia, because it’s required to ensure the correctness of the EBS replication protocol. However, because chain replication requires a configuration change during network partitions, it is especially important for Physalia to be available during partitions.
Physalia then has the goal of optimizing for availability during network partitions, while remaining strongly consistent. Our core observation is that we do not require all keys to be available to all clients. In fact, each key needs to be available at only three points in the network: the AWS EC2 instance that is the client of the volume, the primary copy, and the replica copy. Through careful placement, based on our system’s knowledge of network and power topology, we can significantly increase the probability that Physalia is available to the clients that matter for the keys that matter to those clients.
Brewer’s conjecture and the feasibility of consistent, available, partitiontolerant web services
https://dl.acm.org/doi/10.1145/564585.564601
Linearizability: A correctness condition for concurrent objects
https://dl.acm.org/doi/10.1145/78969.78972
The network is reliable :review
https://dl.acm.org/doi/10.1145/2643130
motivation for physalia
C vs A
This is Physalia’s key contribution, and our motivation for building a new system from the ground up: infrastructure aware placement and careful system design can significantly reduce the effect of network partitions, infrastructure failures, and even software bugs.
compare paxos made live
https://dl.acm.org/doi/10.1145/1281100.1281103
the details, choices and tradeoffs that are required to put a consensus system into production. Our concerns, notably blast radius reduction and infrastructure awareness, are significantly different from that paper
Physalia design goal
- Physalia’s goals of blast radius reduction and partition tolerance required careful attention in the design of the data model, replication mechanism, cluster management and even operational and deployment procedures.
- to be easy and cheap to operate, contributing negligibly to the cost of our dataplane. We wanted its data model to be flexible enough to meet future uses in similar problem spaces, and to be easy to use correctly
- highly scalable,able to support an entire EBS availability zone in a single installation.
Gcm-siv: Full nonce misuse-resistant authenticated encryption at under one cycle per byte
design: nodes, cells and the colony
Physalia’s highlevel organization.
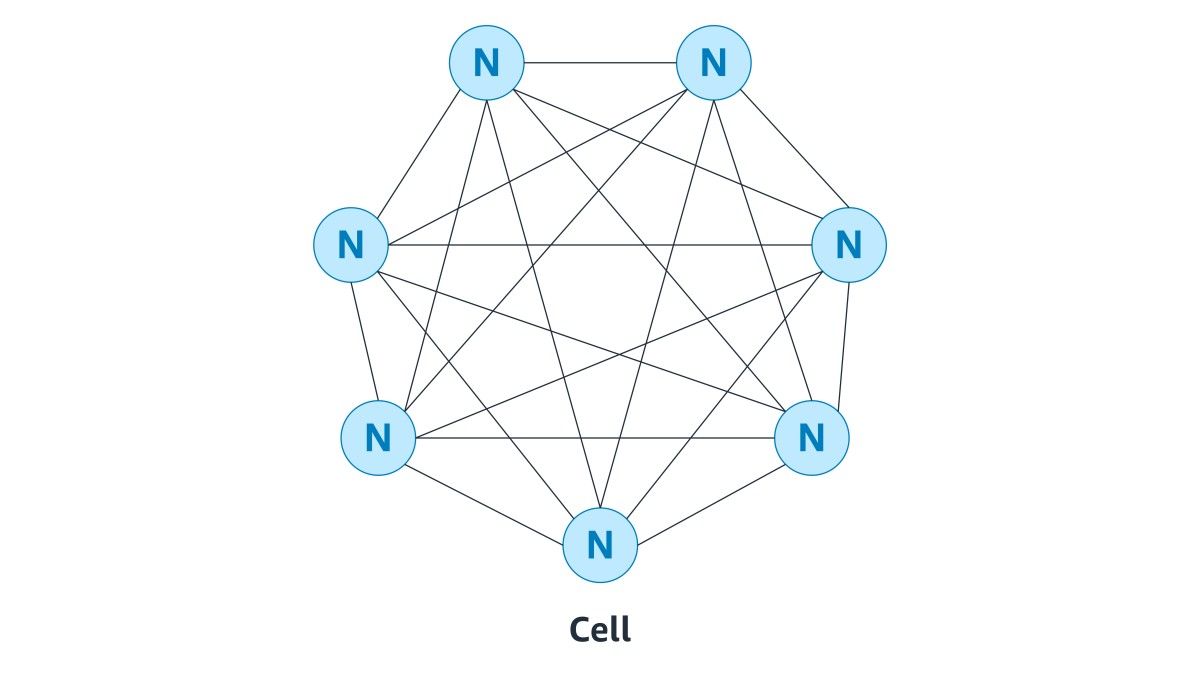
each Physalia installation is a colony, made up of many cells. The cells live in the same environment: a mesh of nodes, with each node running on a single server. Each cell manages the data of a single partition key, and is implemented using a distributed state machine, distributed across seven nodes. Cells do not coordinate with other cells, but each node can participate in many cells. The colony, in turn, can consist of any number of cells (provided there are sufficient nodes to distribute those cells over).
nodes, cells and the colony relation graph
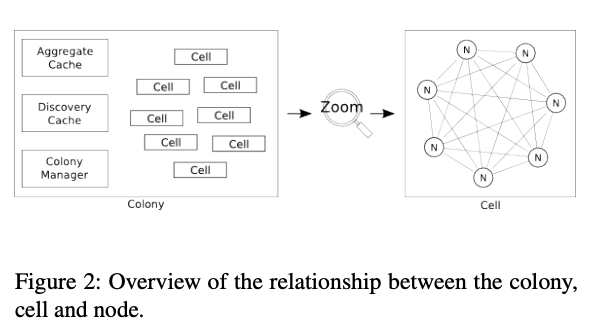
The cells live in the same environment: a mesh of nodes, with each node running on a single server. Each cell manages the data of a single partition
key, and is implemented using a Paxos-based distributed state machine, distributed across seven nodes. Cells do not coordinate with other cells, but each node can participate in many cells
The division of a colony into a large number of cells is our main tool for reducing radius in Physalia. Each node is only used by a small subset of cells, and each cell is only used by a small subset of clients.
cell graph
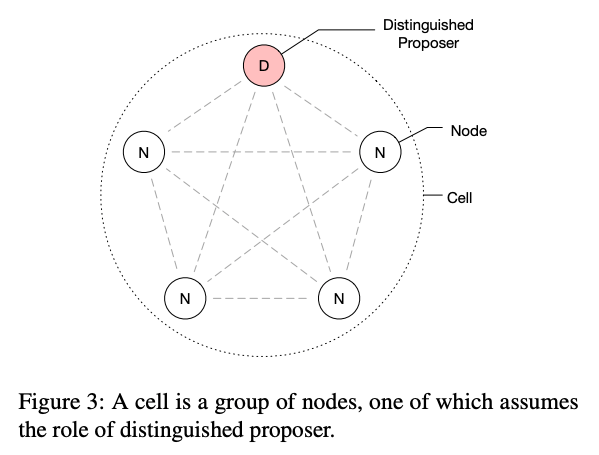
a mesh of nodes holding a single Paxos-based distributed state machine, with one of the nodes playing the role of distinguished proposer.
physalia colony
Each Physalia colony includes a number of control plane components. The control plane plays a critical role in maintaining system properties. When a new cell is created, the control plane uses its knowledge of the power and network
topology of the datacenter (discovered from AWS’s datacenter automation systems) to choose a set of nodes for the cell. The choice of nodes balances two competing priorities. Nodes should be placed close to the clients (where close is measured in logical distance through the network and power topology) to ensure that failures far away from their clients do not cause the cell to fail. They must also be placed with sufficient diversity to ensure that small-scale failures do not cause the cell to fail. Section 3 explores the details of placement’s role in
availability.
how the cell creation and repair?
The cell creation and repair workflows respond to requests to create new cells (by placing them on under-full nodes), handling cells that contain failed nodes (by replacing these nodes), and moving cells closer to their clients as clients move
(by incrementally replacing nodes with closer ones)
the node is the datanode of ebs??
the tradeoff for the control plane as a seperation system
We could have avoided implementing a seperate controlplane and repair workflow for Physalia, by following the example of elastic replication [2] or Scatter [23]. We evaluated these approaches, but decided that the additional complexity, and additional communication and dependencies between shards, were at odds with our focus on blast radius. We chose to keep our cells completely independent, and implement the control plane as a seperate system.
https://doi.org/10.1145/2523616.2523623
https://doi.org/10.1145/2043556.2043559
What is the shards in the Physalia?
Meang impl controlplane along with cell state machines is not proper, so impl as a seperate system now ?
Impl in the chain replication in ebs?
design: cell is falvor of paxos
The design of each cell is a straightforward consensus-based distributed state machine. Cells use Paxos [35] to create an ordered log of updates, with batching and pipelining [48] to improve throughput. Batch sizes and pipeline depths are
kept small, to keep per-item work well bounded and ensure short time-to-recovery in the event of node or network failure.
Physalia uses a custom implementation of Paxos,which keeps all required state both in memory and persisted to disk.
The control plane tries to ensure that each node contains a different mix of cells, which reduces the probability of correlated failure due to load or poison pill transitions. In other words, if a poisonous transition crashes the node software on each node in the cell, only that cell should be lost. In the
EBS deployment of Physalia, we deploy it to large numbers of nodes well-distributed across the datacenter. This gives the Physalia control plane more placement options, allowing it to optimize for widely-spread placement
cell paxos impl use what proposals: optimistic approach
proposals are accepted optimistically. All transactions given to the proposer are proposed, and at the time they are to be applied (i.e. all transactions with
lower log positions have already been applied), they are committed or ignored depending on whether the write conditions pass.
the optimistic approahc advantage and disadvantage
this optimistic approach is that the system always makes progress if clients follow the typical optimistic concurrency control (OCC) pattern.
The disadvantage is that the system may do significant additional work during
contention, passing many proposals that are never committed
optimistic concurrency control (OCC)
why select seven node as a cell paxos
- Durability improves exponentially with larger cell size [29]. Seven replicas means that each piece of data is durable to at least four disks, offering durability around 5000x higher than the 2-replication used for the volume
data - Cell size has little impact on mean latency, but larger cells tend to have lower high percentiles because they better reject the effects of slow nodes, such as those experiencing GC pauses [17].
- The effect of cell size on availability depends on the type of failures expected. smaller cells offer lower availability in the face of small numbers
of uncorrelated node failures, but better availability when the proportion of node failure exceeds 50%. While such high failure rates are rare, they do happen in practice, and a key design concern for Physalia. - Larger cells consume more resources, both because Paxos requires O(cellsize) communication, but also because a larger cell needs to keep more copies of the data. The relatively small transaction rate, and very small data, stored by the EBS use of Physalia made this a minor concern.
design: data model and api
The core of the Physalia data model is a partition key. Each EBS volume is assigned a unique partition key at creation time, and all operations for that volume occur within that partition key. Within each partition key, Physalia offers a transactional store with a typed key-value schema, supporting
strict serializable reads, writes and conditional writes over any combination of keys. It also supports simple in-place operations like atomic increments of integer variables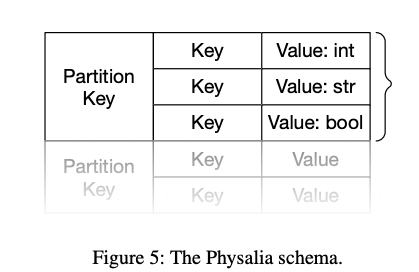
one layer of partition keys, any number (within operational limitations) of string keys within a partition, and one value per key. The API can address only one
partition key at a time, and offers strict serializable batch and conditional operations within the partition.
the design goal balance two competing concerns of the physalia api
balance two competing concerns
- The API needed to be expressive enough for clients to take advantage of the (per-cell) transactional nature of the underlying store, including expressing conditional updates, and atomic batch reads and writes.
- Increasing API expressiveness, on the other hand, increases the probability that the system will be able to accept a transition that cannot be applied (a poison pill).
The Physalia API is inspired by the Amazon DynamoDB API, which supports
atomic batched and single reads and writes, conditional updates, paged scans, and some simple in-place operations like atomic increments. We extended the API by adding a compound read-and-conditional-write operation.
physalia api data feild why not support floating-point data type
Floating-point data types and limited-precision integers are not supported due to difficulties in ensuring that nodes will produce identical results when using different software versions and hardware (see [24] and chapter 11 of [1]).
how support string in the api data feild
Phsyalia’s data fields are strong but dynamically typed. Supported field types include byte arrays (typically used to store UTF-8 string data), arbitrary precision integers, and booleans. Strings are not supported directly, but may be offered as a convenience in the client
As in any distributed state machine, it’s important that each node in a cell gets identical results when applying a transition
why not support sql in the api?
same as floatpoint type
ensure that complex updates are applied the same way by all nodes, across all software versions.
the api support two consistency mode to clients
- In the consistent mode, read and write transactions are both linearizable and serializable, due to being serialized through the state machine log. Most Physalia clients use this consistent mode.
- The eventually consistent mode supports only reads (all writes are consistent), and offers a consistent prefix [7] to all readers and monotonic reads [53] within a single client session. Eventually consistent reads are provided to be used for monitoring and reporting (where the extra cost of linearizing reads worth
it), and the discovery cache (which is eventually consistent anyway).
API Eventually consistent for what usecase
Eventually consistent reads are provided to be used for monitoring and reporting (where the extra cost of linearizing reads worth
it), and the discovery cache (which is eventually consistent anyway).
read and write transactions are both linearizable and serializable meaning
consistent prefix
Rethinking eventual consistency
https://dl.acm.org/doi/10.1145/2463676.2465339
monotonic reads [53] within a single client session
Session guarantees for weakly consistent replicated data
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.71.2269&rep=rep1&type=pdf
read after write
api offer first-class lease
lightweight timebounded locks
The lease implementation is designed to tolerate arbitrary clock skew and short pauses, but will give incorrect results if long-term clock rates are too different. In our implementation, this means that the fastest node clock is advancing at more than three times the rate of the slowest clock. Despite lease safety being highly likely, leases are only used where they are not critical for data safety or integrity.
Leases: An efficient faulttolerant mechanism for distributed file cache consistency
https://dl.acm.org/doi/10.1145/74851.74870
What every computer scientist should know about floating-point arithmetic
https://doi.org/10.1145/103162.103163,doi:10.1145/103162.103163
IEEE standard for floating-point arithmetic. IEEE
Std 754-2008, pages 1–70, Aug 2008
In the API, how proposer batched read /write in a single transaction
In the Physalia API, all keys used to read and write data, as well as conditions for conditional writes, are provided in the input transaction. This allows the proposer to efficiently detect which changes can be safely batched in a single transaction without changing their semantics. When a batch transaction is rejected, for example due to a conditional put failure, the proposer can remove the offending change from the batch and re-submit, or submit those changes without batching.
design: reconfiguration, teaching and learning
As with our core consensus implementation, Physalia does not innovate on reconfiguration.
The approach taken of storing per-cell configuration in the distributed state machine and passing a transition with the existing jury to update it follows
the pattern established by Lampson [37].
How to build a highly available system using consensus Lampson -- reconfigure
https://courses.cs.washington.edu/courses/csep590/04wi/assignments/paxos_lampson.pdf
A significant factor in the complexity of reconfiguration
the interaction with pipelining: configuration changes accepted at log position i
must not take effect logically until position i+α, where α is the maximum allowed pipeline length (illustrated in Figure 6). Physalia keeps α small (typically 3), and so simply waits for natural traffic to cause reconfiguration to take effect (rather than stuffing no-ops into the log). This is a very sharp edge in
Paxos, which doesn’t exist in either Raft [42] or Viewstamped
Replication [41].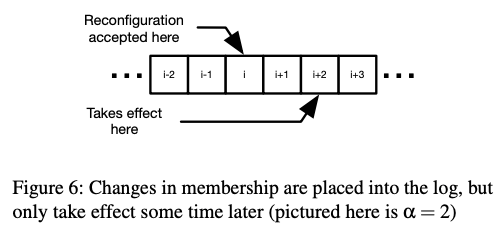
reconfigure in the raft /paxos/ viewstamped replication
raft
In search of an understandable consensus algorithm
https://dl.acm.org/doi/10.5555/2643634.2643666
https://www.usenix.org/system/files/conference/atc14/atc14-paper-ongaro.pdf
viewstamped replication
Viewstamped replication: A new primary copy method to support highly-available distributed systems
https://dl.acm.org/doi/10.1145/62546.62549
physalia reconfiguration is unusual
- reconfiguration happens frequently. The colony-level control plane actively moves Physalia cells to be close to their clients. It does this by replacing far-away nodes with close nodes using reconfiguration. The small data sizes in Physalia make cell reconfiguration an insignificant portion of overall datacenter traffic
how physalia move node to client in cell
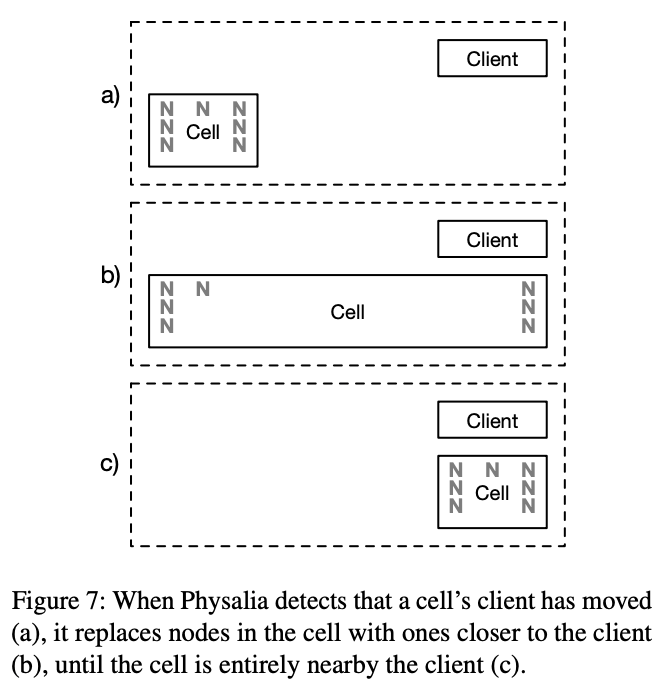
movement by iterative reconfiguration. The system prefers safety over speed, moving a single node at a time (and waiting for that node to catch up) to minimize the impact on durability. The small size of the data in each cell allows reconfiguration to complete quickly, typically allowing movement to complete within a minute.
node join or rejoin a cell by teaching
When nodes join or re-join a cell they are brought up to speed by teaching, a process we implement outside the core consensus protocol.
We support three modes of teaching
- In the bulk mode, most suitable for new nodes, the teacher (any existing node in the cell) transfers a bulk snapshot of its state machine to the learner.
- In the log-based mode, most suitable for nodes re-joining after a partition or pause, the teacher ships a segment of its log to the learner. We have found that this mode is triggered rather frequently in production, due to nodes temporarily falling behind during Java garbage collection pauses. Log-based learning is chosen when the size of the missing log segment is significantly smaller than the
size of the entire dataset. - packet loss and node failures may leave persistent holes in a node’s view of the log. If nodes are not able to find another to teach them the decided value in that log position (or no value has been decided), they use a whack-a-mole learning mode. In whack-a-mole mode, a learner actively tries to propose a no-op transition into the vacant log position. This can have two outcomes: either the acceptors report no other proposals for that log position and the no-op transition is accepted, or another proposal is found and the learner proposes that value. This process is always safe in Paxos, but can affect liveness, so learners apply substantial jitter to whack-a-mole learning.
paxos propser
design: discovery cache
The Discovery Cache where??
Clients find cells using a distributed discovery cache.
The discovery cache is a distributed eventually-consistent cache which allow clients to discover which nodes contain a given cell (and hence a given partition key). Each cell periodically pushes updates to the cache identifying which partition key they hold and their node members. Incorrect information in the cache affects the liveness, but never the correctness, of the system.
reduce the impact of the discovery cache on availability
client-side caching, forwarding pointers, and replication.
First, it is always safe for a client to cache past discovery cache results, allowing them to refresh lazily and continue to use old values for an unbounded period on failure.
Second, Physalia nodes keep long-term (but not indefinite) forwarding pointers when cells move from node to node. Forwarding pointers include pointers to all the nodes in a cell, making it highly likely that a client will succeed in pointer chasing to the current owner provided that it can get to at least one of the past owners.
Finally, because the discovery cache is small, we can economically keep many copies of it, increasing the probability that at least one will be available
system liveness and correctness
design: system model and Byzantine Faults
In designing Physalia, we assumed a system model where messages can be arbitrarily lost, replayed, re-ordered, and modified after transmission. Message authentication is implemented using a cryptographic HMAC on each message,
guarding against corruption occurring in lower layers. Messages which fail authentication are simply discarded. Key distribution, used both for authentication and prevention of unintentional Sybil-style attacks [20] is handled by our environment (and therefore out of the scope of Physalia), optimising for frequent and low-risk key rotation.
This model extends the “benign faults” assumptions of Paxos [11] slightly, but stops short of Byzantine fault tolerance 1 . While Byztantine consensus protocols are well understood, they add significant complexity to both software and
system interactions, as well as testing surface area. Our approach was to keep the software and protocols simpler, and mitigate issues such as network and storage corruption with cryptographic integrity and authentication checks at these
layers.
1 This approach is typical of production consensus-based systems, including popular open-source projects like Zookeeper and etcd.
Sybil-style attacks
Practical byzantine fault tolerance
http://pmg.csail.mit.edu/papers/osdi99.pdf
how build system tolerate faults in single machines, and uncorrelated failures of a small number of machines
use State-machine replication using consensus
In theory, systems built using this pattern can achieve extremely high availability. In practice, however, achieving high availability is challenging
Studies across three decades (including Gray in 1990 [26], Schroeder and Gibson
in 2005 [50] and Yuan et al in 2014 [57]) have found that software, operations, and scale drive downtime in systems designed to tolerate hardware faults. Few studies consider a factor that is especially important to cloud customers: largescale correlated failures which affect many cloud resources at
the same time.
Availability in consensus system: Physalia vs the Monolith
It is well known that it is not possible to offer both all-clients availability and consistency in distributed databases due to the presence of network partitions. It is, however, possible to offer both consistency and availability to clients on the majority side of a network partition. To be as available as possible to its clients, Physalia needs to be on the same side of any network partition as them. client, data master and data replica are nearby each other on the network, and Physalia needs to be nearby too. Reducing the number of network
devices between the Physalia database and its clients reduces the possibility of a network partition forming between them for the simple reason that fewer devices means that there’s less to go wrong.
Physalia also optimizes for blast radius. We are not only concerned with the availability of the whole system, but want to avoid failures of the whole system entirely. When failures happen, due to any cause, they should affect as small a subset of clients as possible. Limiting the number of cells depending on a single node, and clients on a single cell, significantly reduce the effect that one failure can have on the overall system.
A monolithic system has the advantage of less complexity. No need for the discovery cache, most of the control plane, cell creation, placement, etc.. Our experience has shown that simplicity improves availability, so this simplification would be a boon. On the other hand, the monolithic approach loses out on partition tolerance. It needs to make a trade-off between being localized to a small part of the network (and so risking being partitioned away from clients), or being spread over the network (and so risking suffering an internal partition making some part of it unavailable). The monolith also increases blast radius: a single bad software deployment could cause a complete failure (this is similar to the node count trade-off of Figure 4, with one node).
EBS control plane
of which the Physalia control plane is a part
Availability in cs: Placement For Availability
The EBS control plane (of which the Physalia control plane is a part) continuously optimizes the availability of the EBS volume P(Av) to the client AWS EC2 instance, and the EBS storage servers that store the volume.
In terms of the availability of the volume (Av), and the instance (Ai), the control plane optimizes the conditional probability P(Av|Ai).
The ideal solution to this problem is to entirely co-locate the volume and instance, but EBS offers the ability to detach a volume from a failed instance, and re-attach it to another instance. To make this useful, volumes must continue to be durable even if the instance suffers a failure. Placement must therefore balance the concerns of having the volume close enough for correlated availability, but far enough away for sufficiently independent durability to meet EBS’s durability promise.
As an example, consider an idealized datacenter with three levels of network (servers, racks and rows) and three power domains (A, B and C). The client instance is on one rack, the primary copy on another, and replica copy on a third, all within the same row. Physalia’s placement will then ensure that all nodes for the cell are within the row (there’s no point being available if the row is down), but spread across at least three racks to ensure that the loss of one rack doesn’t impact availability. It will also ensure that the nodes are in three different power domains, with no majority in any single domain.
the placement scheme for availability face two challenges
- One is that realworld datacenter topology is significantly more complex
- EBS volumes move by replication, and their clients move by customers detaching their volumes from one instance and attaching them to another. The Physalia control plane continuously responds to these changes in state, moving nodes to ensure that placement constraints continue to be met.
Availability in cs: Non-Infrastructure Availability Concerns
Another significant challenge with building high-availability distributed state machines is correlated work.
In a typical distributed state machine design, each node is processing the
same updates and the same messages in the same order. This leads the software on the machines to be in the same state. In our experience, this is a common cause of outages in realworld systems: redundancy does not add availability if failures
are highly correlated
Software deployments and configuration changes also contribute to downtime. The fault-tolerant nature of distributed state machines makes incremental deplyment approach less effective: because the system is designed to tolerate failure in less than half of hosts, failure may not be evident until new code is deployed to half of all hosts. Positive validation, where the deployment system checks that new nodes are taking traffic, reduce but do not eliminate this risk
Poison pills are a particularly interesting case of software failure.
All of these factors limit the availability of any single distributed state machine, as observed by its clients. To achieve maximum availability, we need many such systems spread throughout the datacenter. This was the guiding principle of
Physalia: instead of one database, build millions.
Poison pills
a particularly interesting case of software failure. A poison pill is a transaction which passes validation and is accepted into the log, but cannot be applied without causing an error. poison pills are typically caused by under-specification in the transaction logic ("what does dividing by zero do?", "what does it mean to decrement an unsigned zero?"), and are fixed by fully specifying these behaviors (a change which comes with it’s own backward-compatibility challenges).
Availability in cs: operational practices
operations, including code and configuration deployments, routine system operations such as security patching, and scaling for increased load, are dominant contributors to system downtime, despite ongoing investments in reducing operational defect rates.
Operational practices at AWS already separate operational tasks by region and availability zone, ensuring that operations are not performed across many
of these units at the same time.
Physalia goes a step further than this practice, by introducing the notion of colors. Each cell is assigned a color, and each cell is constructed only of nodes of the same color. The control plane ensures that colors are evenly spread around the datacenter, and color choice minimally constrains how close a cell can be to its clients.
When software deployments and other operations are performed, they proceed color-by-color. Monitoring and metrics are set up to look for anomalies in single colors. Colors also provide a layer of isolation against load-related and poison pill failures. Nodes of different colors don’t communicate with each other, making it significantly less likely that a poison pill or overload could spread across
colors.
Availability in cs: Load in Sometimes-Coordinating Systems
Load is another leading cause of correlated failures.
a consensus-based system needs to include more than half of all nodes in each consensus decision, which means that overload can take out more than half of all nodes. Colors play a role in reducing the blast radius from load spikes from a few clients, but the load on Physalia is inherently spiky.
During normal operation, load consists of a low rate of calls caused by the background rate of EBS storage server failures, and creation of new cells for new volumes. During large-scale failures, however, load can increase considerably. This is an inherent risk of sometimes-coordinating systems like EBS: recovery load is not constant, and highest during bad network or power conditions.
Per-cell Physalia throughput, as is typical of Paxos-style systems, scales well up to a point, with significant wins coming from increased batch efficiency. Beyond this point, however, contention and the costs of co-ordination cause goodput to drop with increased load (as predicted by Gunther’s model [28]). To avoid getting into this reduced-goodput mode, cells reject load once their pipelines are full.
Clients are expected to exponentially backoff, apply jitter, and eventually retry their rejected transactions. As the number of clients in the Physalia system is bounded,this places an absolute upper limit on load, at the cost of latency during overload.
jitter client
design ,build, test,evaluation
testing
Testing needs to cover not only the happy case, but also a wide variety of
error cases
jepsen test framework
error handling is where many bugs hide out
network partitions are rare events that easily hide bugs
many consensus implementations also have bugs in the happy path.
build a test harness which abstracts networking, performance, and other systems concepts (we call it a simworld).
The goal of this approach is to allow developers to write distributed systems tests, including tests that simulate packet loss, server failures, corruption, and other failure cases, as unit tests in the same language as the system itself. In this case, these unit tests run inside the developer’s IDE (or with junit at build time), with no need for test clusters or other infrastructure
The key to building a simworld is to build code against abstract physical layers (such as networks, clocks, and disks).
- In addition to unit testing simworld, we adopted a number of other testing approaches. One of those approaches was a suite of automatically-generated tests which run the Paxos implementation through every combination of packet loss and reordering that a node can experience. This testing approach was inspired by the TLC model checker [56], and helped us build confidence that our implementation matched the formal specification
- used the open source Jepsen tool [33] to test the system, and make sure that the API responses are linearizable under network failure cases. This testing, which happens at the infrastructure level, was a good complement to our lowerlevel tests as it could exercise some under-load cases that are hard to run in the simworld.
- a number of game days against deployments of Physalia. A game day is a failure simulation that happens in a real production or production-like deployment of a system, an approach that has been popular at Amazon for 20 years. similar to the chaos engineering approach pioneered by Netflix [32], but typically focuses on larger-scale failures rather than component failures
The Role of Formal Methods
aws Simworld java
netflix chaos enginner
Netflix Simian Army, 2011. URL:
https://medium.com/netflix-techblog/the-netflix-simian-army-16e57fbab116
jepson io
Model checking tla+ specifications TLC model checker
https://dl.acm.org/doi/10.5555/646704.702012
test formal method
TLA+ [36] is a specification language that’s well suited to building formal models of concurrent and distributed systems. We use TLA+ extensively at Amazon [39], and it proved exceptionally useful in the development of Physalia
https://dl.acm.org/doi/10.1145/2736348?dl=ACM&coll=portal
How Amazon web services uses formal methods
https://dl.acm.org/doi/10.1145/2699417?dl=ACM&coll=portal
Our team used TLA+ in three ways: writing specifications of our protocols to check that we understand them deeply, model checking specifications against correctness and liveness properties using the TLC model checker, and writing extensively
commented TLA+ code to serve as the documentation of our distributed protocols
While all three of these uses added value, TLA+’s role as a sort of automatically tested (via TLC), and extremely precise, format for protocol documentation was
perhaps the most useful. Our code reviews, simworld tests, and design meetings frequently referred back to the TLA+ models of our protocols to resolve ambiguities in Java code or written communication. We highly recommend TLA+ (and
its Pluscal dialect) for this use.
split brain
quorum jury
ABA problem
evaluation need to dive
Evaluating the performance of a system like Physalia is challenging
Performance, including throughput and latency, are important, but the most important performance metrics are how the system performs during extremely rare large-scale outages.We evaluate the performance of Physalia in production, and evaluate the design through simulations. We also use simulations to explore some particularly challenging wholesystem aspects of Physalia.
diff with distributed co-ordination system
Distributed co-ordination systems, like Zookeeper [19], Chubby [9], Boxwood [38] and etcd [14], have the goal of providing a highly-available and strongly-consistent set of basic operations that make implementing larger distributed systems easier. Physalia’s design approach is similar to some of these systems, being based on the state machine replication pattern popularized by the work
of Schneider [49], Oki [40] and Lampson [37]. Physalia’s key differences from these systems are its fine-grained consensus (millions of distributed state machines, rather than a single one), and infrastructure awareness. This makes Physalia more scalable and more resistant to network partitions, but also
significantly more complex.
Physalia draws ideas from both distributed co-ordination systems and distributed databases
diff with highly-available distributed storage in fallible datacenter networks
The problem of providing highly-available distributed storage in fallible datacenter networks faces similar challenges to global and large-scale systems like OceanStore [34] and Farsite [3], with emphasis on moving data close to its expected to improve availability and latency. While the design of Physalia predates the publication of Spanner [15] and CosmosDB, Physalia takes some similar design approaches with similar motivation.
diff with horizontal partitioning of database
Systems like Dynamo [18] and its derivatives dynamically move partitions, and rely
on client behavior or stateless proxies for data discovery. Dynamic discovery of high-cardinality data, as addressed by Physalia’s discovery cache and forwarding pointers, has been well explored by systems like Pastry [47] and Chord [52].
Optimizing data placement for throughput and latency is also a well-established technique (such as in Tao [8], and Dabek et al [16]), but these systems are not primarily concerned with availability during partitions, and do not consider blast radius
infrastructure-aware placement
reflects some techniques from software-defined networking (SDN) [21]. Another similarity with SDN (and earlier systems, like RCP [10]) is the emphasis on separating control and data planes, and allowing the data plane to consist of simple packet-forwarding elements. This reflects similar decisions to separate Physalia from the data plane of EBS, and the dataand control planes of Physalia itself.
Some systems (like SAUCR [4], and the model proposed by Chen et al [13]) are designed to change operating modes when infrastructure failures occur or request
patterns change, but we are not aware of other database explicitly designed to include data placement based on network topology (beyond simple locality concerns)
conclusion
Physalia is a classic consensus-based database which takes a novel approach to availability: it is aware of the topology and datacenter power and networking, as well as the location of the clients that are most likely to need each row, and uses data placement to reduce the probability of network partitions. This
approach was validated using simulation, and the gains have been borne out by our experience running it in production at high scale across over 60 datacenter-scale deployments. Its design is also optimized to reduce blast radius, reducing the
impact of any single node, software, or infrastructure failure.
While few applications have the same constraints that we faced, many emerging cloud patterns require strongly consistent access to local data. Having a highly-available stronglyconsistent database as a basic primitive allows these systems
to be simpler, more efficient, and offer better availability
ref
https://www.usenix.org/system/files/nsdi20-paper-brooker.pdf
https://www.usenix.org/sites/default/files/conference/protected-files/nsdi20_slides_brooker.pdf
https://www.usenix.org/conference/nsdi20/presentation/brooker
https://www.amazon.science/blog/amazon-ebs-addresses-the-challenge-of-the-cap-theorem-at-scale
avalibiry
raid /failover /replication
block diagram
what are the components, what does each of them own, and how do they communicate to other components.
Getting the block diagram right helps with the design of database schemas and APIs, helps reason through the availability and cost of running the system, and even helps form the right org chart to build the design.
control plane
when doing these design exercises is to separate components into a control plane and a data plane, recognizing the differences in requirements between these two roles.
Along with the monolithic application itself, storage and load balancing are data plane concerns: they are required to be up for any request to succeed, and scale O(N) with the number of requests the system handles. On the other hand, failure tolerance, scaling and deployments are control plane concerns: they scale differently (either with a small multiple of N, with the rate of change of N, or with the rate of change of the software) and can break for some period of time before customers notice.
Every distributed system has components that fall roughly into these two roles: data plane components that sit on the request path, and control plane components which help that data plane do its work. Sometimes, the control plane components aren't components at all, and rather people and processes, but the pattern is the same.
https://brooker.co.za/blog/2019/03/17/control.html
https://www.cs.cornell.edu/home/rvr/papers/OSDI04.pdf
what physalia store
The master stores a small amount of configuration data indicating which servers hold the data for a given volume and the order in which they replicate it, which is important for identifying up-to-date data. The replication protocol uses the configuration data to decide where application data should be stored, and it updates the configuration to point to the application data’s new location. Physalia is designed to play the role of the configuration master.
cell node vs ebs volume machines
maybe colocated, maybe seperatedly
formal method in aws
How Amazon web services uses formal methods
https://dl.acm.org/doi/10.1145/2699417?dl=ACM&coll=portal
https://assets.amazon.science/fa/fb/fe142b0c4b3eab3ec3d15794e025/one-click-formal-methods.pdf
https://www.amazon.science/publications/reachability-analysis-for-aws-based-networks
http://lamport.azurewebsites.net/tla/formal-methods-amazon.pdf
http://lamport.azurewebsites.net/tla/tla.html
can we repartition into another cell?
one EBS volume -> a single cell (with 7 nodes, replicating all the key set). what if shard is still big? can we repartition into another cell? now single EBS volume key points to two cells? Or am i something missing here?
%
since the emphasis is on 'tiny databases' I suspect that repartitioning / splits is out of scope.
its configuration db, volume size not matter. Single EBS Volume has Single Cell. Must be enough.
When they say Single Key Transactional store, does mean its not “MVCC” right?
meaning we just don’t care about multiple keys consistency in a single transaction correct?
%
multiple keys in a single partition can be updated in a single txn (section 2.3 Within each partition key, Physalia offers a transactional store with a typed key-value schema, supporting strict serializable reads, writes and conditional writes over any combination of keys.).Here the key is not the partition key.
Transactions are totally ordered, and are applied atomically, but I’m not sure there’s no need for concurrency control. Concurrency control is a property of a transaction manager in combination with storage engine. If I understand it correctly, you need it even in a single node database, let alone a distributed one.Can you elaborate why you think there’s no need for it in this case? Another example of a db that has total ordering but still needs concurrency control (pessimistic, in this case) is calvin.
total order doesn’t really preclude concurrent execution. It just means that order is predetermined.
I'm pretty sure you do need isolation, within a single partition, since there are multi-key general transactions. That's handled by serializing through Paxos, IIUC.
You need CC if you execute your totally ordered transactions concurrently.
total order of transaction vs ioslation
You need CC if you execute your totally ordered transactions concurrently.
however, it is only in case if the transactions that they have are not CAS
if they are CAS I can'd imagine they can get out of Paxos uncommitted
%
They're not just CAS. The only thing they do is gather their read sets at the beginning of the txn (like Calvin I think?).
If I recall correctly, both RAMP and Calvin do that. Not exactly same thing though: RAMP can collect writes for overlapping transactions, and Calvin collects data that satisfies the read set.
how cc impl in the physalia
still think that if they have CC, it is something very simple, and considering its a configuration DB, the write throughput is such small that maybe its even single-threaded (no cc, just sequential application of mutations) (however, its blind guesses)
right; in any event, since most storage engines are built for transactionality, you sort of have to implement CC one way or the other, even if you don’t use it for imposing order, whether it’s LSM, B-Tree or anything else I’m aware of..
2:10
I’m not arguing about the specific use-case/implementation though. Maybe they have partitioned store, maybe they’re just single-threaded. I was speaking more of a general case
get the picture of kind of configs are exactly stored in there as key value store? Just SD info, replicas info?
The master stores a small amount of configuration data indicating which servers hold the data for a given volume and the order in which they replicate it, which is important for identifying up-to-date data. from author’s blog.
A small favor
Was anything I wrote confusing, outdated, or incorrect? Please let me know! Just write a few words below and I'll be sure to amend this post with your suggestions.
Follow along
If you want to know about new posts, add your email below. Alternatively, you can subscribe with RSS.